In the modern era of the sport each car can have between 150 and 300 sensors, generating an approximate of 300gb of data per car per grand prix weekend. This is of great use for the engineers who can make data-driven decisions in order to extract the maximum performance out of the car on each event; however, this wasn’t always the case. In the early days of the sport it was technologically impossible to generate or store these amounts of data.
Most of this information is publicly available in tidy format in some websites, APIs and python packages, such as, the fastf1 python library. Early formula 1 data is also available on the FIA’s website, but mostly in the form of html tables. Therefore, if we want to analyze this data we will have to scrape it.
Webscrapping code
We will import the tidyverse library, which is a collection of packages very useful for data wrangling. The main package we’ll use for webscrapping is the rvest package, we will also need the stringr package, which allows us to manipulate more easily string-type variables.
1
2
| library(tidyverse)
library(rvest)
|
We will store our main site links from where the scrapping will start.
1
2
| link_fia <- "https://fiaresultsandstatistics.motorsportstats.com"
link_seasons <- "https://fiaresultsandstatistics.motorsportstats.com/series/formula-one/season/"
|
If we add a specif year to the link_seasons string, it will take us to the main page of that F1 season. The read_html, extracts all html code from the site, from there we can retrieve specific nodes. Let’s go to the link of the first Formula 1 grand prix ever.
1
2
3
4
5
6
| link_british_1950 <- "https://fiaresultsandstatistics.motorsportstats.com/results/1950-british-grand-prix/classification"
british_1950_page <- read_html(link_british_1950)
british_1950_race <- british_1950_page |>
html_table()
british_1950_race
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ## [[1]]
## # A tibble: 21 × 12
## Pos No Driver Nat Team Laps Time Gap Interval Kph Best Lap
## <chr> <int> <chr> <chr> <chr> <int> <chr> <chr> <chr> <dbl> <chr> <int>
## 1 1 2 Nino Fa… Italy Alfa… 70 2:13… "" "" 146. "1:5… 2
## 2 2 3 Luigi F… Italy Alfa… 70 2:13… "+ 2… "+ 2.60… 146. "" NA
## 3 3 4 Reg Par… Grea… Alfa… 70 2:14… "+ 5… "+ 49.4… 145. "" NA
## 4 4 14 Yves Gi… Fran… Auto… 68 2:13… "2 L… "2 Laps" 142. "1:5… 41
## 5 5 15 Louis R… Fran… Auto… 68 2:14… "2 L… "+ 1:03… 141. "1:5… 10
## 6 6 12 Bob Ger… Grea… Bob … 67 2:13… "3 L… "1 Lap" 140. "" NA
## 7 7 11 Cuth Ha… Grea… Cuth… 67 2:13… "3 L… "+ 0.40… 140. "" NA
## 8 8 16 Philipp… Fran… Auto… 65 2:14… "5 L… "2 Laps" 135. "1:5… 31
## 9 9 6 David H… Grea… Scud… 64 2:14… "6 L… "1 Lap" 133. "" NA
## 10 10 10 Joe Fry… Grea… Joe … 64 2:15… "6 L… "+ 56.8… 132. "" NA
## # ℹ 11 more rows
|
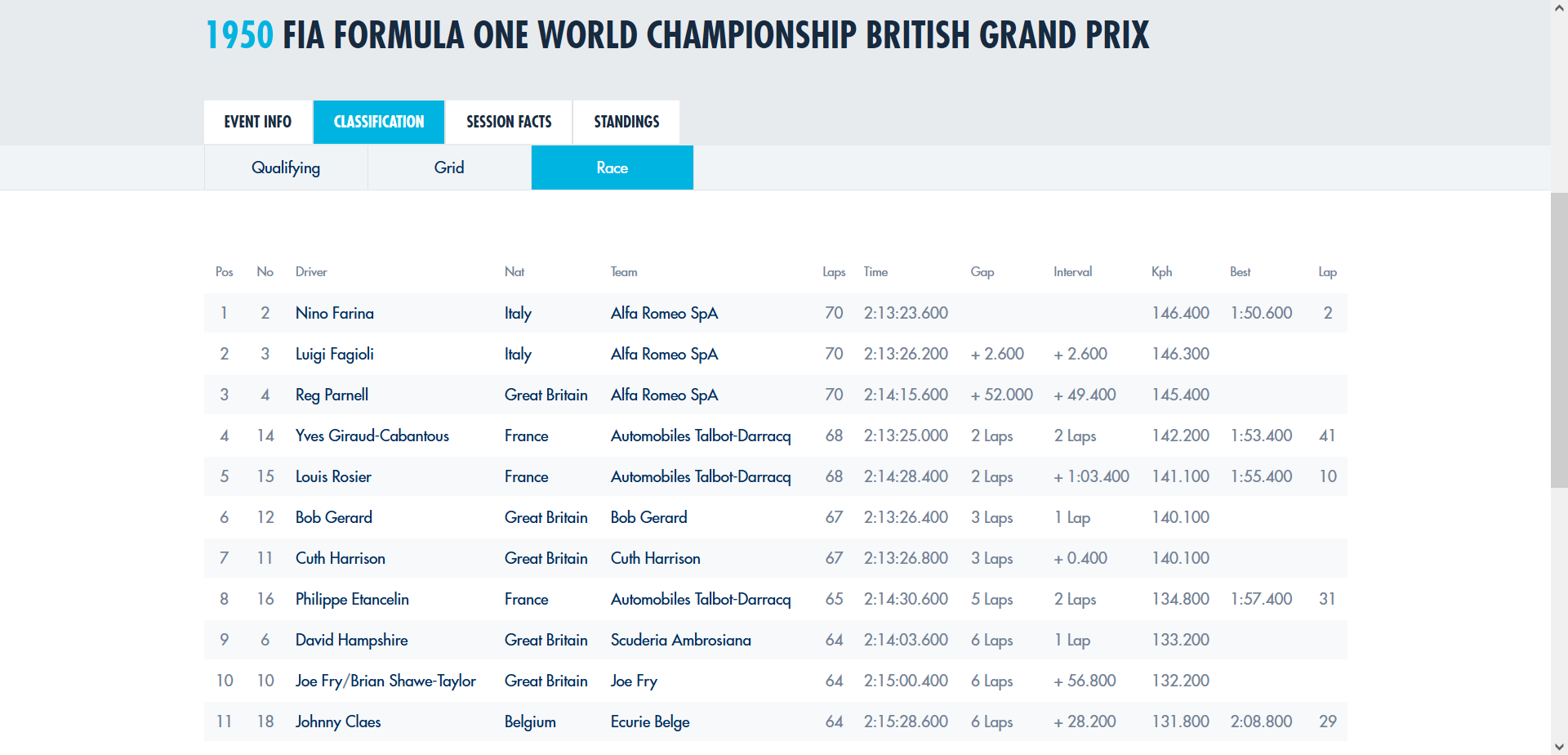
Here the html_table function retrieves a list of tibbles of all html tables on the page, fortunately, in this case there was only table. The tibble consists of the position a certain driver finished, the laps ran, the total race time, average speed, and their fastest lap of the race and in which lap was completed, as well as, the drivers’ team and nationality. Let’s look at a screenshot of the webpage for comparison.
If we navigate to the site, we can see that there’s a menu right above the race positions table, which has the buttons: “Qualifying”, “Grid” and “Race”, these buttons have hyperlinks which will take you to another page. We already have the race information, but we are also interested in the qualifying data, we know that in html the hyperlinks are stored in “a” nodes, so we can use the following code to retrieve the link to the qualifying page.
1
2
3
4
5
6
7
| href_qual <- british_1950_page |>
html_node(xpath = "//a[text() = 'Qualifying']") |>
html_attr("href")
british_1950_qual_link <- paste0(link_fia, href_qual)
british_1950_qual_link
|
1
| ## [1] "https://fiaresultsandstatistics.motorsportstats.com/results/1950-british-grand-prix/classification/310d5889-6079-4841-a8df-cb6d92de54d1"
|
Here we are asking R to retrieve the “a” html node that contains the text “Qualifying”, and get the hyperlink of that node, then we paste that to the url for our main site. We can use the same function as with race data, to get a tibble of qualifying positions.
1
2
3
4
| british_1950_qual <- read_html(british_1950_qual_link) |>
html_table()
british_1950_qual
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ## [[1]]
## # A tibble: 21 × 12
## Pos No Driver Nat Team Laps Time Gap Interval Kph Best Lap
## <int> <int> <chr> <chr> <chr> <lgl> <chr> <chr> <chr> <dbl> <lgl> <lgl>
## 1 1 2 Nino Fa… Italy Alfa… NA 1:50… "" "" 151. NA NA
## 2 2 3 Luigi F… Italy Alfa… NA 1:51… "+ 0… "+ 0.20… 151. NA NA
## 3 3 1 Juan Ma… Arge… Alfa… NA 1:51… "+ 0… "" 151. NA NA
## 4 4 4 Reg Par… Grea… Alfa… NA 1:52… "+ 1… "+ 1.20… 149. NA NA
## 5 5 21 Prince … Thai… Enri… NA 1:52… "+ 1… "+ 0.40… 149. NA NA
## 6 6 14 Yves Gi… Fran… Auto… NA 1:53… "+ 2… "+ 0.80… 148. NA NA
## 7 7 17 Eugene … Fran… Auto… NA 1:55… "+ 4… "+ 2.00… 145. NA NA
## 8 8 20 Emmanue… Swit… Enri… NA 1:55… "+ 5… "+ 0.40… 145. NA NA
## 9 9 15 Louis R… Fran… Auto… NA 1:56… "+ 5… "+ 0.20… 144. NA NA
## 10 10 9 Peter W… Grea… Pete… NA 1:56… "+ 5… "+ 0.60… 144. NA NA
## # ℹ 11 more rows
|
Above the Qualifying, Grid and Race menu there’s another menu with buttons: “Event Info”, “Classification”, “Session Facts” and “Standings”. The race and qualifying data are under the classification page; however, under event info. there’s information about the engine and car each driver was running, which might be important in other analysis. We can use the same trick to get the link to this page, and then retrieve the table.
1
2
3
4
5
6
7
8
| href_event <- british_1950_page |>
html_nodes(xpath = "//a[text() = 'Event Info']") |>
html_attr("href")
british_1950_event <- read_html(paste0(link_fia, href_event)) |>
html_table()
british_1950_event
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ## [[1]]
## # A tibble: 23 × 6
## `#` Driver Nat Team Car Engine
## <int> <chr> <chr> <chr> <chr> <chr>
## 1 1 Juan Manuel Fangio Argentina Alfa Romeo SpA Alfa Romeo… Alfa …
## 2 2 Nino Farina Italy Alfa Romeo SpA Alfa Romeo… Alfa …
## 3 3 Luigi Fagioli Italy Alfa Romeo SpA Alfa Romeo… Alfa …
## 4 4 Reg Parnell Great Britain Alfa Romeo SpA Alfa Romeo… Alfa …
## 5 5 David Murray Great Britain Scuderia Ambrosiana Maserati 4… Maser…
## 6 6 David Hampshire Great Britain Scuderia Ambrosiana Maserati 4… Maser…
## 7 8 Leslie Johnson Great Britain T A S O Mathieson ERA E ERA
## 8 9 Peter Walker Great Britain Peter Walker ERA E ERA
## 9 9 Tony Rolt Great Britain Peter Walker ERA E ERA
## 10 10 Joe Fry Great Britain Joe Fry Maserati 4… Maser…
## # ℹ 13 more rows
|
Under the “Session Facts” section there’s a lap by lap positions chart, which might be useful to retrieve. The horizontal axis of this chart are the race positions, while the vertical axis has the lap numbers, while the cell value is the driver’s number.
1
2
3
4
5
6
7
8
9
10
| href <- british_1950_page |>
html_nodes(xpath = "//a[text() = 'Session Facts']") |>
html_attr("href")
href2 <- read_html(paste0(link_fia, href)) |>
html_nodes(xpath = "//a[text() = 'Lap Chart']") |>
html_attr("href")
lap_chart_link <- paste0(link_fia, href2)
lap_chart_link
|
1
| ## [1] "https://fiaresultsandstatistics.motorsportstats.com/results/1950-british-grand-prix/session-facts/4817f4b9-6d84-4ea2-9c5b-ff9dcff6f2e7?fact=LapChart"
|
1
2
| read_html(lap_chart_link) |>
html_table()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| ## [[1]]
## # A tibble: 71 × 1
## Pos.
## <chr>
## 1 Grid
## 2 Lap 1
## 3 Lap 2
## 4 Lap 3
## 5 Lap 4
## 6 Lap 5
## 7 Lap 6
## 8 Lap 7
## 9 Lap 8
## 10 Lap 9
## # ℹ 61 more rows
|
If we go to the site we can see that there’s a lap by lap positions table, but this can’t be retrieved using the html_table function, so we will have to go a little deeper into the html code. Using inspect mode in the web browser we see that the elements of the chart are under div nodes with a specif class:
1
2
3
4
5
6
| lap_chart_page <- read_html(lap_chart_link)
div_nodes <- lap_chart_page |>
html_nodes(xpath = "//div[@class='_1BvfV']")
div_nodes
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ## {xml_nodeset (1491)}
## [1] <div class="_1BvfV">2</div>\n
## [2] <div class="_1BvfV">2</div>\n
## [3] <div class="_1BvfV">2</div>\n
## [4] <div class="_1BvfV">2</div>\n
## [5] <div class="_1BvfV">2</div>\n
## [6] <div class="_1BvfV">2</div>\n
## [7] <div class="_1BvfV">2</div>\n
## [8] <div class="_1BvfV">2</div>\n
## [9] <div class="_1BvfV">2</div>\n
## [10] <div class="_1BvfV">2</div>\n
## [11] <div class="_1BvfV">3</div>\n
## [12] <div class="_1BvfV">3</div>\n
## [13] <div class="_1BvfV">3</div>\n
## [14] <div class="_1BvfV">3</div>\n
## [15] <div class="_1BvfV">3</div>\n
## [16] <div class="_1BvfV">1</div>\n
## [17] <div class="_1BvfV">2</div>\n
## [18] <div class="_1BvfV">2</div>\n
## [19] <div class="_1BvfV">2</div>\n
## [20] <div class="_1BvfV">2</div>\n
## ...
|
If this was a regular square chart, we could just use the html_text function to retrieve a string-type array of the text inside the div nodes and then convert it to matrix; however, if we take a look at the chart on the site we can see that it has an irregular form since some drivers retire from the race at different stages. Therefore, the number of columns (positions in the race) is constantly shrinking. This leaves a lot empty cells in the table, i.e div nodes with no text attribute, so they can’t be retrieve with the html_text function.
To work around this issue we will have to consider each div node as a character variable, from the above output we can see that all nodes follow the same pattern. We will use the regexpr function to extract the values between <div> and <\div>, if there’s nothing between them, we can just store an empty string.
1
2
3
4
5
6
7
8
9
10
11
12
| div_char <- as.character(div_nodes)
my_numbers <- character(length(div_char))
for (k in seq_along(div_char)){
match <- regexpr("(?<=<div class=\"_1BvfV\">)\\d*(?=</div>\\n)", div_char[k], perl = TRUE)
if (match > 0) { # If there's something there store it in the vector
my_numbers[k] <- substr(div_char[k], match, match + attr(match, "match.length") - 1)
} else { # If there isn't anything there store an empty value
my_numbers[k] <- " "
}
}
head(my_numbers, 20)
|
1
2
| ## [1] "2" "2" "2" "2" "2" "2" "2" "2" "2" "2" "3" "3" "3" "3" "3" "1" "2" "2" "2"
## [20] "2"
|
The next step is to build a tibble from this array, for that we need to retrieve the number of drivers who started the race, which is the same as the number of columns of our chart. We use the inspect mode again to retrieve the div class in which the column names are stored. We extract the text under these nodes, and pull the last value.
1
2
3
4
5
6
7
| total_drivers <- read_html(lap_chart_link) |>
html_nodes(xpath = "//div[@class='_3DVzL']") |>
html_text() |> tail(1) |> as.numeric()
# Make the character vector a matrix of total_drivers columns, just realize that not all charts
lap_chart <- as_tibble(matrix(my_numbers, ncol = total_drivers))
lap_chart
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| ## # A tibble: 71 × 21
## V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 2 3 1 4 21 14 17 20 15 19 8 12 16
## 2 2 3 1 4 21 20 17 14 15 16 12 11 6
## 3 2 3 1 4 21 20 17 14 15 16 12 11 6
## 4 2 3 1 4 21 17 20 14 15 16 12 11 6
## 5 2 3 1 4 21 17 20 14 15 16 12 11 6
## 6 2 3 1 4 21 17 20 14 15 16 12 11 6
## 7 2 3 1 4 21 17 20 14 15 16 12 11 6
## 8 2 3 1 4 21 17 20 14 15 16 12 11 6
## 9 2 3 1 4 21 17 20 14 15 16 12 11 6
## 10 2 3 1 4 21 20 14 15 16 12 11 6 5
## # ℹ 61 more rows
## # ℹ 8 more variables: V14 <chr>, V15 <chr>, V16 <chr>, V17 <chr>, V18 <chr>,
## # V19 <chr>, V20 <chr>, V21 <chr>
|
Thank you for reading this webscrapping exercise, hope you find it useful. If you want to see the full code and subsequent analysis check out my github repo.